
스트림과 병렬처리
스트림
스트림은 반복자
컬렉션(배열 포함)의 요소를 하나씩 참조해서 람다식으로 처리할 수 있는 반복자임.
- java 7 이전 코드
List<String> list = Arrays.asList("홍길동", "도우너", "마이콜"); Iterator<String> iterator = list.iterator(); while(iterator.hasNext()){ String name = iterator.next(); System.out.print(name); } - java 8 이후 코드
List<String> list = Arrays.asList("홍길동", "도우너", "마이콜"); Stream<String> stream = list.stream(); stream.forEach(name -> System.out.print(name));
스트림 특징
- 람다식으로 요소 처리 코드를 제공
- 스트림이 제공하는 대부분의 요소 처리 메소드는 함수적 인터페이스 매개타입을 가짐.
- 매개값으로 람다식 또는 메소드 참조를 대입할 수 있음.
public static void main(String[] args) { List<Student> list = Arrays.asList( new Student("홍길동", 100), new Student("고길동", 50) ); Stream<Student> stream = list.stream(); stream.forEach(s ->{ String name = s.getName(); int score = s.getScore(); System.out.print(name + score); }); }
- 내부 반복자를 사용하므로 병렬 처리가 쉬움.
- 외부 반복자(external iterator)
- 개발자가 코드로 직접 컬렉션 요소를 반복해서 요청하고 가져오는 코드 패턴
- 내부 반복자(internal iterator)
- 컬렉션 내부에서 요소들을 반복시키고 개발자는 요소당 처리해야할 코드만 제공하는 코드 패턴
- 내부 반복자 이점
- 개발자는 요소 처리 코드에만 집중
- 멀티코어 CPU를 최대한 활용하기 위해 요소들을 분배시켜 병렬 처리 작업을 할 수 있음.
- 병렬(parallel)처리
- 한가지 작업을 서브 작업으로 나눈 뒤
- 서브 작업들을 분리된 스레드에서 병렬적으로 처리 후
- 서브 작업들을 최종 결합하는 방법
- 서브 작업들을 분리된 스레드에서 병렬적으로 처리 후
- 자바는 ForkJoinPool 프레임워크를 이용해 병렬 처리 함.
- 한가지 작업을 서브 작업으로 나눈 뒤
- 외부 반복자(external iterator)
- 병렬처리 코드 예제
public static void main(String[] args) { List<String> list = Arrays.asList("고길동","마이콜","도우너","둘리","희동이"); Stream<String> stream = list.stream(); stream.forEach(ParallelEx::print); Stream<String> parallelStream = list.parallelStream(); parallelStream.forEach(ParallelEx::print); } public static void print(String string) { System.out.print(string + " : " + Thread.currentThread().getName()); }고길동 : main 마이콜 : main 도우너 : main 둘리 : main 희동이 : main 도우너 : main 둘리 : ForkJoinPool.commonPool-worker-2 고길동 : ForkJoinPool.commonPool-worker-2 희동이 : main 마이콜 : ForkJoinPool.commonPool-worker-1 - 스트림은 중간 처리와 최종 처리를 할 수 있음.
- 중간 처리 : 요소들의 매핑, 필터링, 정렬
- 최종 처리 : 반복, 카운트, 평균, 총합
```java
public static void main(String[] args) {
List
list = Arrays.asList( new Student("고길동", 90), new Student("도우너", 92), new Student("마이콜", 100) );
double avg = list.stream().mapToInt(Student::getScore).average().getAsDouble(); System.out.print(“평균 : “ + avg); } ```
- 최종 처리 : 반복, 카운트, 평균, 총합
```java
public static void main(String[] args) {
List
- 중간 처리 : 요소들의 매핑, 필터링, 정렬
스트림의 종류
스트림의 포함된 패키지
- 자바 8부터 java.util.stream 패키지에서 인터페이스 타입으로 제공
- 모든 스트림에서 사용할 수 있는 공통 메소드들이 정의되어 있는 BaseStream 아래에 객체와 타입 요소를 처리하는 스트림이 있음.
- BaseStream은 공통 메소드들이 정의되어 있고, 코드에서 직접적으로 사용하지 않음.
- BaseStream
- Stream
- IntStream
- LongStream
- DoubleStream
컬렉션으로부터 스트림 얻기
public void Stream01() {
List<Student> studentList = Arrays.asList(
new Student("고길동", 10),
new Student("마이콜", 20),
new Student("도우너", 30)
);
Stream<Student> stream = studentList.stream();
stream.forEach(s -> System.out.print(s.getName()));
}
배열로부터 스트림 얻기
public void Stream02() {
String[] arr = {"고길동","마이콜","도우너"};
Stream<String> stream = Arrays.stream(arr);
stream.forEach(a -> System.out.print(a));
System.out.print();
int[] intArr = {1,2,3};
IntStream intStream = Arrays.stream(intArr);
intStream.forEach(a -> System.out.print(a));
}
숫자 범위로부터 스트림 얻기
public void Stream03() {
IntStream stream = IntStream.rangeClosed(1, 100);
stream.forEach(a -> sum += a);
System.out.print(sum);
}
파일로부터 스트림 얻기
public void Stream04() {
Path path = Paths.get("C:\\Workspaces\\java_workspace\\student\\src\\data.txt");
Stream<String> stream;
try {
stream = Files.lines(path, Charset.defaultCharset());
stream.forEach(System.out::print);
stream.close();
System.out.print();
File file = path.toFile();
FileReader fileReader = new FileReader(file);
BufferedReader bufferedReader = new BufferedReader(fileReader);
stream = bufferedReader.lines();
stream.forEach(System.out::print);
stream.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
디렉토리로부터 스트림 얻기
public void Stream05() {
Stream<Path> stream;
try {
Path path = Paths.get("C:\\Workspaces\\java_workspace\\student\\src");
stream = Files.list(path);
stream.forEach(p -> System.out.print(p.getFileName()));
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
스트림 파이프라인
중간 처리와 최종 처리
- 리덕션(Reduction)
- 대량의 데이터를 가공해서 축소하는 것을 말함.
- 합계, 평균값, 카운팅, 최대값, 최소값등을 집계하는 것
- 요소가 리덕션의 결과물로 바로 집계할 수 없을 경우 중간 처리가 필요함.
- 중간처리 : 필터링, 매핑, 정렬,그룹핑
- 중간 처리한 요소를 최종처리해서 리덕션 결과물을 산출함.
- 대량의 데이터를 가공해서 축소하는 것을 말함.
- 스트림은 중간 처리와 최종 처리를 파이프라인으로 해결함.
- 파이프라인(pipelines) : 스트림을 파이프처럼 이어놓은것
- 중간처리 메소드(필터링,매핑,정렬)는 중간처리된 스트림을 리턴
- 이스트림에서 다시 중간처리 메소드를 호출해서 파이프 라인을 형성
- 최종 스트림의 집계 기능이 시작되기 전까지 중간 처리는 지연(lazy)됨.
- 최종 스트림이 시작하면 비로소 컬렉션에서 요소가 하나씩 중간 스트림에서 처리되고 최종 스트림까지 오게 됨.
- 파이프라인(pipelines) : 스트림을 파이프처럼 이어놓은것
- 예제) 회원 컬렉션에서 남자회원의 평균 나이
Stream<Member> maleFemaleStream = list.stream(); Stream<Member> maleStream = maleFemaleStream.filter(m -> m.getSex() == Member.MALE); IntStream ageStream = maleFemaleStream.mapToInt(Member::getAge); OptionalDouble optionalDouble = ageStream.average(); double ageAvg = optionalDouble.getAsDouble();double ageAvg = list.stream() //오리지널 스트림 .filter(m -> m.getSex() == Member.MALE) //중간 처리 스트림 .mapToInt(Member::getAge) // 중간처리 스트림 .average() // 최종 처리 .getAsDouble(); - 예제 코드
public static void main(String[] args) {
List<Member> list = Arrays.asList(
new Member("홍길동", Member.MALE, 30),
new Member("나으리", Member.FEMALE, 20),
new Member("둘리", Member.FEMALE, 21),
new Member("고길동", Member.MALE, 40)
);
double avg = list.stream()
.filter(m -> m.getSex() == Member.MALE)
.mapToInt(Member::getAge)
.average()
.getAsDouble();
System.out.println(avg);
}
중간 처리 메소드와 최종 처리 메소드
- 리턴 타입을 보면 중간 처리 메소드인지 최종처리 메소드인지 구분가능함.
- 중간 처리 메소드 : 리턴 타입이 스트림
- 최종 처리 메소드 : 리턴 타입이 기본타입이거나 OptionalXXX
- 중간 처리 메소드
- 중간 처리 메소드는 최종 처리 메소드가 실행되기 전까지 지연함.
- 최정 처리 메소드가 실행 되어야만 동작을 함.

-
최종 처리 메소드
필터링 중간처리 - distinct(), filter()
- 중간 처리 기능으로 요소를 걸러내는 역할을 함.
| 리턴 타입 | 메소드(매개변수) | 설명 |
|---|---|---|
| Stream IntStream LongStream DoubleStream |
distinct() | 중복제거 |
| Stream IntStream LongStream DoubleStream |
filter(Predicate) filter(IntPredicate) filter(LongPredicate) filter(DoublePredicate) |
조건 필터링 |
- distinct()
- 중복을 제거하는 스트림 필터링 메소드
- Stream : equals() 메소드가 true 가 나오면 동일한 객체로 판단하고 중복을 제거
- IntStream, LongStream, DoubleStream : 동일값일 경우 중복 제거
- filter()
- 매개값으로 주어진 Predicate 가 true 를 리턴하는 요소만 필터링 함.
distinct(), filter() 실습예제
- distinct() 로 List 에 저장된 중복 객체를 제거
- filter() 를 통해 조건에 맞는 객체만 찾음
- forEach()를 통해 하나씩 출력
public class FilterEx {
public static void main(String[] args) {
List<String> names = Arrays.asList("홍","길","동","홍","길","동");
names.stream().distinct() //중복제거
.forEach(System.out::print);
System.out.println();
names.stream().filter(str -> str.startsWith("길")) //조건에 맞는 객체만 찾음
.forEach(System.out::print);
System.out.println();
names.stream().distinct().filter(str -> str.endsWith("동"))
.forEach(System.out::print);
System.out.println();
}
}
매핑 중간처리 - flatMapXXX(), mapXXX(), asXXXStream(),box
- 매핑(mapping)은 중간처리 기능으로 스트림의 요소를 다른 요소로 대체
- 예를 들어 객체를 정수, double, boolean 값으로 대체하는것
- 반드시 하나의 요소가 대체되는것은 아니며, 하나의 요소가 여러개의 요소로 대체 될 수 있음.
- 매핑 메소드 종류
- flatMapXXX(), mapXXX(), asDoubleStream(), asLongStream(), boxed();
flatMapXXX() 메소드
- 한개의 요소를 대체하는 복수개의 요소들로 구성된 새로운 스트림
- 다음 예제는 입력된 데이터(요소)들이 List
에 저장되어있다고 가정하고, 요소별로 단어를 뽑아 단어 스트림으로 재생성함. 만약 입력된 데이터들이 숫자면 숫자를 뽑아 숫자 스트림으로 재생성함.
- 다음 예제는 입력된 데이터(요소)들이 List
mapXXX() 메소드
- 요소를 대체하는 요소로 구성된 새로운 스트림을 리턴
- flatMapXXX() 메소드는 하나의 요소를 여러개의 요소로 대체하고, mapXXX() 메소드는 하나의 요소로 대체함.
asDoubleStream(), asLongStream(),boxed() 메소드
- asDoubleStream()
- IntStream()의 int요소 또는 LongStream의 Long 요소를 double 요소로 타입변환해서 DoubleStream 을 생성
- asLongStream()
- IntStream() 의 int요소를 Long요소로 타입변환해서 LongStream을 생성
- boxed()
- int 요소(), long 요소, double 요소를 Integer, Long, Double 요소로 박싱해서 Stream 을 생성
정렬 중간 처리 - sorted()
- 중간 처리 기능으로 최종 처리되기 전에 요소를 정렬
- 객체 요소일 경우에는 Comparable 을 구현하지 않으면 첫번째 sorted() 메소드를 호출하면 ClassCastException 이 발생
- 객체 요소가 Comparable 을 구현하지 않았거나, 구현 했다하더라도, 다른 비교 방법으로 정렬하려면 Comparator 를 매개값으로 갖는 두번째 sorted() 메소드를 사용해야함.
- Comparator 함수적 인터페이스이므로 다음과 같이 람다식으로 매개값 작성
sorted((a,b) -? {...}) - 중괄호
{}안에는 a와 b를 비교해서 a가 작으면 음수, 같으면 () a가 크면 양수를 리턴하는 코드를 작성
- Comparator 함수적 인터페이스이므로 다음과 같이 람다식으로 매개값 작성
- 정렬 코드 예
- 객체 요소가 Comparable 을 구현하고있고, 기본 비교(Comparable) 방법으로 정렬
- 다음 세가지 방법 중 하나를 선택
sorted(); sorted((a,b) -> a.compareTo(b)); sorted(Comparator.naturalOrder());
- 요소가 Comparable 을 구현하고 있지만, 기본 비교 방법과 정반대 방법으로 정렬
- 위에서의 정렬 방법과 정반대의 결과가 나옴
sorted((a,b) -> b.compareTo(a)); sorted(Comparator.reverseOrder());
- 위에서의 정렬 방법과 정반대의 결과가 나옴
루핑(looping)
- 중간 또는 최종 처리 기능으로 요소 전체를 반복하는것을 말함.
- 루핑 메소드
- peek() : 중간 처리메소드
- 최종 처리 메소드가 실행되지 않으면 지연되기 때문에 최종처리 메소드가 호출되어야만 동작함.
- 루핑 미동작
intStream.filter(a->a % 2==0).peek(System.out::println); - 루핑 동작
intStream.filter(a->a % 2==0).peek(System.out::println).sum();
- forEach() : 최종 처리 메소드
intStream.filter(a -> a % 2 == 0).forEach(System.out::println);
- peek() : 중간 처리메소드
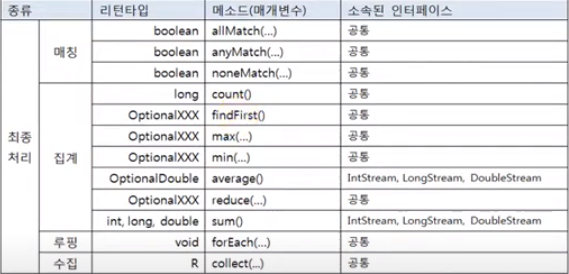
매칭(matching) 최종 처리
- 최종 처리 기능으로 요소들이 특정 조건을 만족하는지 조사하는것
- 매칭 메소드
- allMatch()
- 모든 요소들이 매개값으로 주어진 predicate 의 조건을 만족하는지 조사
- anyMatch()
- 최소한 한개의 요소가 매개값으로 주어진 Predicate 의 조건을 만족하는지 조사
- noneMatch()
- 모든 요소들이 매개값으로 주어진 Predicate 의 조건을 만족하지 않는지 조사
- allMatch()
기본 집계 최종 처리
집계(Aggregate)
- 최종 처리 기능
- 카운팅,합계,평균값,최대값,최소값등과 같이 하나의 값으로 산출함.
- 대량의 데이터를 가공해서 축하는 리덕션(Reduction) 이라고 볼 수있음.
- OptionalXX 클래스
- 자바 8부터 추가된 값을 저장하는 값 기반 클래스
- java.util 패키지의 Optional, OptionalDouble, OptionalInt, OptionalLong 클래스를 말함.
- 저장된 값을 얻으려면 get(),getAsDouble(), getAsInt(),getAsLong() 메소드를 호출
Optional 클래스
- 값을 저장하는 값 기반 클래스
- Optional, OptionalDouble, OptionalInt, OptionalLong
- 집계 메소드의 리턴 타입으로 사용되어 집계 값을 가지고 있음.
- 특징
- 집계 값이 존재하지 않을 경우 디폴트 값을 설정할 수도 있음.
- 집계 값을 처리하는 Consumer 를 등록 할 수 있음.
커스텀 집계 - reduce()
reduce() 메소드
- 프로그램화해서 다양한 집계(리덕션) 결과물을 만들수 있음.
- Stream 인터페이스 타입의 두 메소드
- 첫번째 메소드는 BinaryOperator를 매개 변수로 받으므로 두값의 연산 결과를 Optional하게 리턴한다는 의미
- 두번째 메소드는 두 값의 연산결과를 리턴하되, 결과가 없다면(연산이 안되는 경우 즉, 두개의 요소가 없는 예외 발생 경우 NoSuchElementException) default 로 identity 값을 리턴한다는 의미
- Stream 인터페이스 타입의 두 메소드
- 매개변수
- XXXBinaryOperator : 두개의 매개값을 받아 연산 후 리턴하는 함수적 인터페이스
- identity : 스트림에 요소가 전혀 없을 경우 리턴될 디폴트 값
수집 최종 처리 - collect()
- 최종 처리 기능으로 요소들을 수집 또는 그룹핑함.
- 필터링 또는 매핑된 요소들로 구성된 새로운 컬렉션을 생성
- 요소들을 그룹핑하고, 집계(리덕션)을 할 수 있음.
- 예를들어, 전체 학생 요소들 중에서 남학생과 여학생을 따로 그룹핑하여 집계 가능함. 필터링한 요소 수집
- Collector 의 타입 파라미터
- T : 요소
- A : 누적기(accumulator)
- R : 요소가 저장될 새로운 컬렉션
- ==> T요소를 A누적기가 R에 저장함.
- Collector 의 구현 객체
- Collectors 클래스의 정적 메소드를 이용
- A(누적기)가 ?인 이유
- List,Set,Map 컬렉션에 누적할 경우에는 이미 Collector 에서 어느 켈렉션에 저장하는지 알기 때문에 별도의 A(누적기)가 필요없음.
- 전체 학생 List에서 남학생들만 별도의 List로 생성
List<Student> maleList= totalList.stream() .filter(s -> s.getSex() == Student.Sex.MALE) .collect(Collectors.toList()); - 전체 학생 List에서 여학생들만 별도의 HashSet으로 생성
- HashSet 객체를 Supplier 가 생성하도록 함.
- Collectors.toSet()을 이용해도 상관 없음
Set<Student> femaleSet = totalList.stream() .filter(s -> s.getSex() == Student.Sex.FEMALE) .collect(Collectors.toCollection(HashSet::new));